Principes#
- Auteur:
Étienne Loks - Valérie-Emma Leroux - Yann Le Jeune
- Date:
2020-11-23
- Copyright:
CC-BY 3.0
Ce document présente les grands principes qui structurent Ishtar.
Présentation#
Présentation générale#
Ishtar est un projet de gestion de base de données visant à gérer les données et la documentation (mobilier inclus) provenant d'opérations archéologique, publié sous la forme d'un logiciel libre sous licence AGPL 3.0 (ou supérieure).
L'objectif est d'assurer une traçabilité maximale des informations afin de faire vivre cette documentation et la rendre même éventuellement accessible au public ou encore à un (ou des) groupe(s) d'utilisateurs.
Ce logiciel a vocation à être installé sur un serveur web mais peut également fonctionner en local, à l'échelle d'un chantier, d'une commune ou d'une région entière.
Conçu afin de permettre une communication inter-bases, le projet Ishtar vise plutôt un modèle d'information distribué que centralisé : la communication entre les bases est favorisée.
Il est organisé autour d'un tronc commun associé à des modules liés à des besoins « métiers » spécifiques : administration des opérations et inventaires, lieux de conservation, traitements liés aux laboratoires de restauration, analyse stratigraphique avancée, étiquetage QR-code, etc.
De multiples niveaux d'utilisateurs sont possibles, d'un accès pour le public (ou non) à des accès pour chercheurs, responsables d'opérations, gestionnaires de CCE, connexion avec un SIG, etc.
Voici quelques exemples des usages possibles (liste non exhaustive) pour la gestion des données :
d'une opération programmée ou préventive (une instance pour une opération ou une série d'opérations) gérée à l'échelle de l'équipe de recherche associée : gestion des données, mise en commun, production automatique d'inventaires conformes, export et import d'inventaires avec des spécialistes, gestion des relations stratigraphiques, etc. ;
d'une association de bénévoles : enregistrement des résultats de chacun dans une base commune ;
à l'échelle d'un service régional de l'archéologie : gestion des inventaires mobilier, opérations, dossiers d'urbanisme, rapports, dépôts, production d'arrêtés et de courriers, base de connaissances régionale, etc. ;
pour un service de collectivité territoriale : suivi des opérations, gestion de l'ensemble des données et mise à disposition du public et chercheurs ;
pour un laboratoire de restauration : gestion fine des traitements et traçabilité maximale du mobilier (tout l'historique des traitements est conservé) ;
pour un PCR : plate-forme de synthèse des données collectées et valorisation du travail effectué par l'ouverture au public de la base une fois le PCR achevé ;
pour des étudiants : base de données gratuite, utilisant des normes standardisées, possibilité de mettre en commun son travail avec d'autres, de le faire suivre par des tuteurs ou encadrants ;
etc.
Fonctionnalités#
La version actuelle permet d'accomplir les tâches suivantes :
Module Base (« opérations ») et fonctionnalités transversales
saisie des opérations,
saisie des unités d'enregistrement (UE),
saisie du mobilier archéologique,
association à de la documentation,
gestion des médias (stockage et gestion des photos, pdf des rapports, etc.),
production automatique d'inventaires conformes (UE, mobilier, documents),
imports paramétrables et archivables, incluant éventuellement les liens vers des images, depuis des fichiers tabulaires (format csv, fichier zip pour les images),
recherches diverses, en texte libre ou par paramètres, avec affichage des résultats sous forme de tableaux, galeries d'images et statistiques paramétrables,
exports (csv) suite à une recherche ou par élément sélectionné (opération, UE, mobilier),
génération automatiques de documents d'après des patrons au format odt (format OpenDocument lisible par Libre/Open Office et Word),
production de fiches types pour les opérations, UE ou mobilier (format odt et pdf),
personnalisation des formulaires (ajouts de champs personnalisés, choix de l'affichage des champs Ishtar),
fédération d’instances : Une instance source peut partager en lecture un sous-ensemble de ses données avec des instances destinataires, avec possibilité d’export (Partage contrôlable et sécurisé)
Module Dossiers/administratif
saisie des dossiers,
ajout d'actes administratifs (courriers, arrêtés, etc.),
production automatique de courriers administratifs (accusés de réception, etc.),
Module Opérateur préventif (extension du module dossier)
rédaction de plan d’intervention,
gestion / suivi des coûts (coûts forfaitaires ou à l’unité, en fouille, post-fouille, estimés et réels).
Module Site/Entité archéologique
saisie de données archéologiques connues,
association à des opérations en cours,
exports (csv) suite à une recherche ou par élément sélectionné.
Module Unités d’enregistrements
saisie des unités d'enregistrement (UE) en lien avec une OA,
association à un numéro de parcelle.
Module Mobilier
saisie du mobilier,
association à une UE,
association a de la documentation.
Module Lieux de conservation
gestion des mouvements de mobilier,
production automatique de documents tels conventions de prêts, fiches d'état, etc.
conditionnement,
sélection par « panier »,
gestion des contenants et étiquetage (patrons odt),
Module Conservation
ajout de champs propres à la conservation dans le formulaire mobilier,
gestion des traitements (on peut documenter tous les évènements d'un mobilier après sa mise au jour, que ce soit une radiographie, une restauration ou un prêt pour une exposition, ...),
gestion des demandes de traitement (enregistrement des demandes reçues, exemple demande de prêt pour étude ou exposition),
génération automatique de documents administratifs liés (convention de dépôt, etc.),
Module Archéologie sous-marine
ajout de champs propres à l'archéologie sous-marine dans les différents formulaires,
Module Cartographie
gestion des différents système de coordonnées de référence (SRC) via leurs codes EPSG,
gestion des coordonnées (mobilier, unités d'enregistrements, sites, opérations archéologiques, communes) sous forme de point et/ou polygone,
affichage des résultats de recherche sous forme cartographique,
connexion (jointure) avec un SIG (testé avec QGIS).
Module Musée
ajout de champs propres à la régie des collections muséales dans le formulaire mobilier.
Portail
portail public vitrine (mini-CMS fonctionnant avec une API Ishtar, permettant l'affichage de paniers de mobilier avec leurs notices).
Modules / configuration#
Selon le périmètre fonctionnel dans lequel Ishtar est utilisé, il convient d'activer ou désactiver certains modules. Ces modules permettent d'accéder à plus ou moins de fonctionnalités d'Ishtar, de faire apparaître des champs sur les formulaires, de présenter différemment les données, etc.
Note
L'activation / désactivation d'un module ne change jamais la structure des données. Il est tout à fait possible d'activer ponctuellement un module sans que cela n'altère les données en base.
Des dépendances entre modules existent. Ces dépendances sont logiques et se comprennent aisément si l'on a intégré la structure de la base de données d'Ishtar (cf. Structure de la base de données). Si une dépendance est manquante lors de l'activation du module un message explicite est donné.
L'activation des modules est faite en administration sur la page de configuration d'instance Ishtar (cf. documentation administration applicative).
Par ailleurs au niveau de la configuration d'instance Ishtar un certain de nombre de paramètres de fonctionnement Ishtar peuvent être ajustés. Ceux-ci sont détaillés dans la documentation administration applicative.
Avertissement
Contrairement à l'activation des modules, certains paramètres ont une incidence importante sur les données stockées dans Ishtar, notamment en ce qui concerne la gestion des identifiants mobiliers, des identifiants documents, etc. En tant qu'administrateur, si vous souhaitez une configuration différente de la configuration par défaut d'Ishtar, il est nécessaire de modifier ces paramètres en amont.
Structure de la base de données#
La base de données n'est pas détaillée table par table dans cette documentation mais nous allons vous présenter les grandes notions utilisées. La structure présentée peut apparaître rigide mais c'est un mal nécessaire pour une certaine standardisation des données archéologiques. Par ailleurs les concepts sont très larges et d'expérience s'adapte très bien à la plupart des contextes.
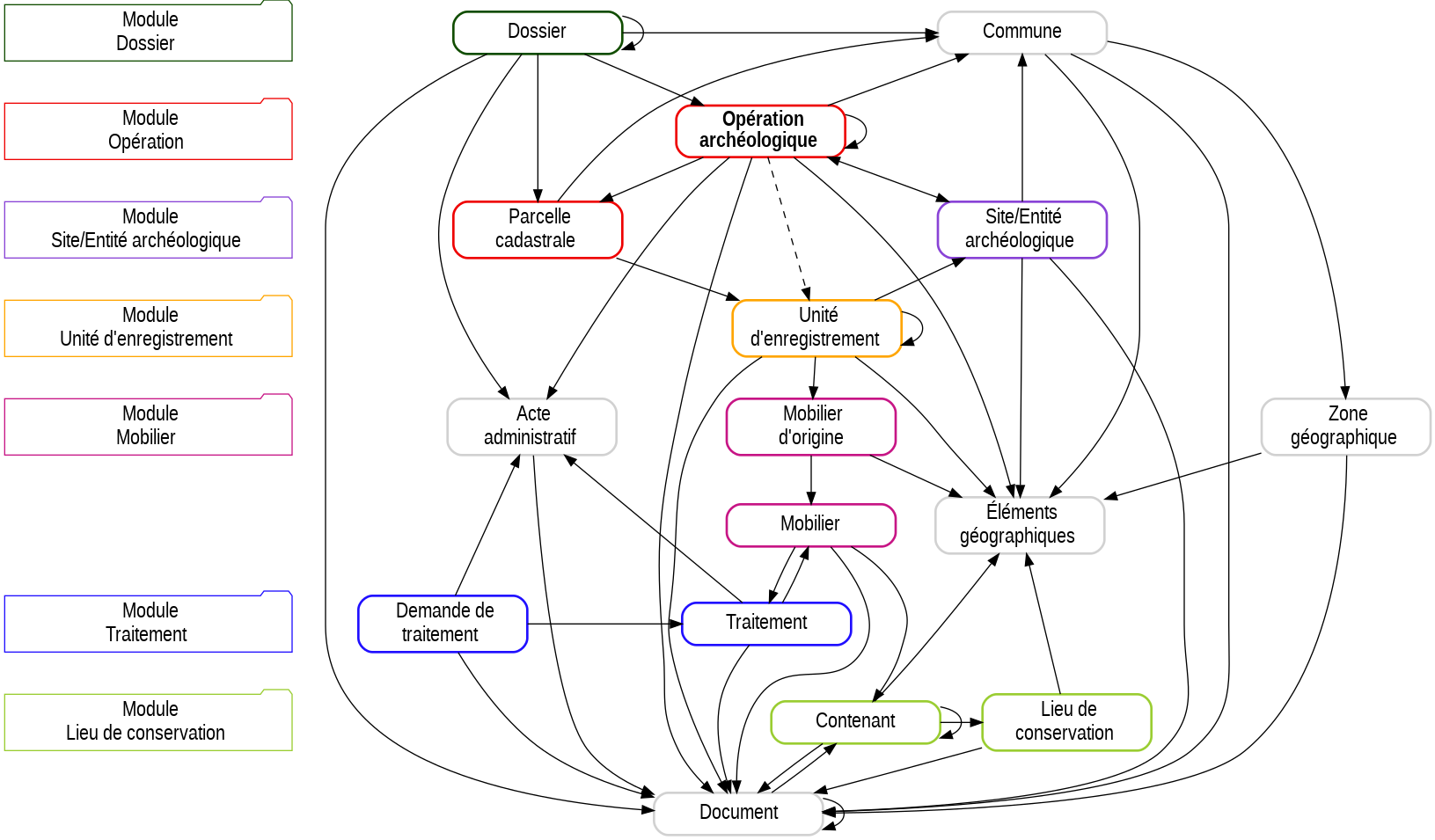
Opération archéologique#
L'opération archéologique est le cœur du modèle de données d'Ishtar. Au sein d'Ishtar, l'opération archéologique est définie comme une action (ou un projet d'action) permettant d'acquérir des données archéologiques, sous la responsabilité d'une personne (exemples : découverte fortuite, diagnostic, fouille programmée, prospection, etc.) et dans un lieu si possible défini.
Si l'opération est au centre du modèle de données d'Ishtar plutôt que le site (ou l'entité archéologique), c'est parce que ce dernier est une interprétation des données (et comme toute interprétation, sujette à évolution dans le temps), alors que l'opération est l'information qui permet au mieux de regrouper un corpus documentaire cohérent mettant en lien des documents (plans, rapports, photos, etc.) et du mobilier.
Il est possible de créer des liens entre des opérations, soit en les associant à un même dossier source (avec le module « administratif », ex. : un permis de construire qui est associé à un diagnostic et une fouille préventive), soit en définissant une relation entre des opérations globales (ex. : PCR, suivi d'autoroutes, etc.) et d'autres plus ponctuelles (phases, tranches, secteurs, etc.). Le regroupement d'opérations est également pratique en contexte de fouilles programmées, où il peut être utile d'avoir des inventaires pour chaque opération par année, mais également une vision globale de la succession des fouilles (opération globale). En contexte de grande opération préventive, ce système peut servir à individualiser des secteurs de fouilles disposant de modes d’enregistrements spécifiques. L'utilisateur a toute latitude pour organiser les opérations entres elles selon ses besoins, du moment que ces éléments clefs représentent bien des lots documentaires et mobilier a priori cohérents.
Site/entité archéologique#
Malgré le choix de l'opération comme rôle central de son modèle de données, Ishtar gère pleinement les sites (ou entité - notion paramétrable en administration) archéologiques et la migration depuis une base orientée site est tout à fait envisageable.
Parcelle#
Les parcelles sont gérées précisément au sein d'Ishtar en étant directement rattachées aux UE. Cela permet de faciliter la gestion des questions légales concernant le mobilier (réalisation du « partage » ou responsabilité en cas de restauration). Si la parcelle de l'UE n'est pas connue ou si l'instance n'est pas sujette a contrainte légale, il est possible d'associer une parcelle inconnue ou de ne pas renseigner ce champ.
Unité d'enregistrement#
La notion d'Unité d'enregistrement (UE) est à prendre comme un concept large. Elle se définit comme étant un volume (ou une surface) référencé dans l'espace (précisément ou non), associé à des informations archéologiques et contenant (ou pas) du mobilier. La proue du navire, la tranchée 3, la structure ST25, l'US137 ou le quart NE du carré A3 sont tous des UE valides pour Ishtar.
Ishtar gère les relations entre UE. Cela permet notamment de définir des UE emboîtées (par exemple : tranchée > structure > US) mais aussi de gérer les relations stratigraphiques entre US.
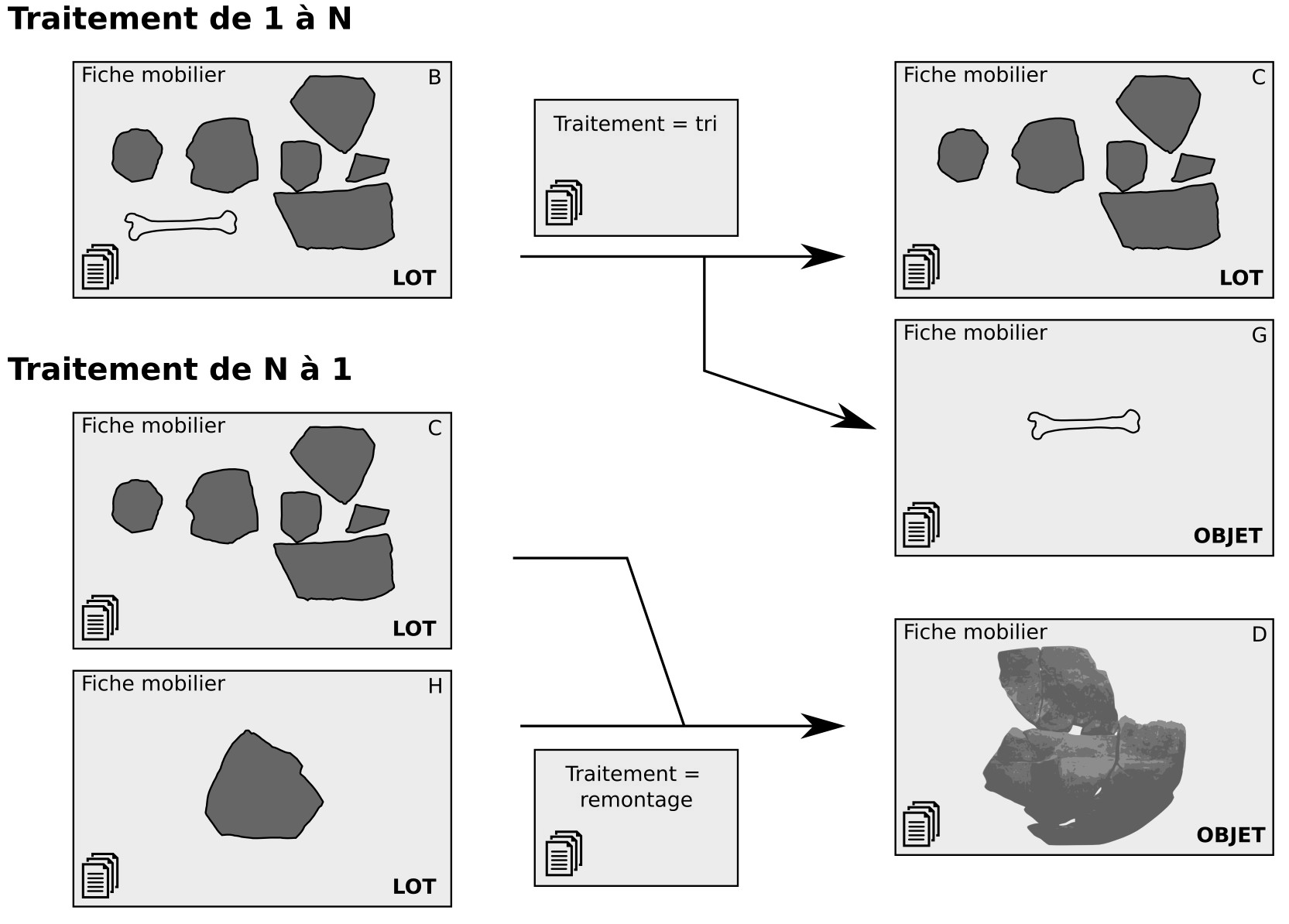
Mobilier - Traitement#
Un traitement est défini comme une action portée par un responsable sur du mobilier archéologique dans un lieu donné. Dans ce cadre, un lavage, une restauration, un prélèvement pour analyse, une radiographie, une étude, un conditionnement, un prêt pour exposition ou une mise en dépôt sont tous des traitements (que le gestionnaire de mobilier est libre d'enregistrer ou non).
Un traitement peut mener à ce que plusieurs objets ou lots deviennent un seul lot ou objet (un remontage par exemple : N à 1), ou à l'inverse qu'un objet suite à un traitement en devienne plusieurs (1 à N).
Le mobilier tel qu'habituellement compris se découpe en deux sous-éléments au sein d'Ishtar :
le mobilier d'origine ;
le mobilier (actuel).
Le mobilier d'origine comprend les informations invariantes tout au long de la vie de l'objet, telle que son contexte de découverte, son inventeur, etc. Le mobilier actuel (généralement juste appelé « mobilier » au sein d'Ishtar) permet de caractériser l'objet tout au long de sa vie.
Le distinguo entre ces deux notions permet notamment une gestion fine des traitements simples (destructif ou non) et complexes (tri, remontage, etc.) avec une connaissance précise de l'historique de l'objet (lieux, responsables et documentations peuvent être associées à chaque traitement).
Sur la figure ci-dessous chaque « Fiche mobilier » correspond à un élément « mobilier actuel » en base de données. Chaque élément et chaque traitement a une fiche associée.
Mobilier - Demande de traitement#
La gestion des demandes de traitement au sein d'Ishtar est prévue pour permettre d'archiver les documents liés à toute demande ou préparation de traitement. Elle permet de générer automatiquement des documents liés à chaque contexte.
Par exemple, lors de la réception d'une demande de prêt de mobilier pour une expo, créer une demande de traitement dans Ishtar permet d'enregistrer la demande, puis de générer automatiquement (selon les patrons de documents définis sur l'instance) une réponse de refus ou au contraire une convention de prêt (à la suite de quoi, une fois la convention dûment signée, l'on créera le traitement Prêt associé).
Lors d'un besoin de restauration, créer une demande de traitement dans Ishtar permet de générer une demande de devis, puis éventuellement d'archiver les devis reçus, avant de créer le traitement Restauration avec le prestataire choisi.
Contenant#
La notion de Contenant est très générique. En effet, un étage, une salle, une étagère sont des contenants au même titre qu'une boîte. Chaque contenant peut contenir du mobilier ou de la documentation mais aussi d'autres contenants. Chaque type de contenant peut être qualifié de mobile (ex : caisse, boîte, carton, palette) ou immobile (ex : étage, salle, travée, étagère, vitrine).
Document#
Les documents sont gérés de manière transversale et peuvent être librement associés à un ou plusieurs éléments (opération, site, UE, traitement, mobilier, etc.) de la base de données. Des méta-données peuvent être renseignées pour chacun de ces documents et une image et/ou un fichier peuvent être le cas échéant adjoints.
Les flux de données#
Pour alimenter Ishtar en données, on distingue 3 modes opératoires :
l'import,
l'ajout/modification par formulaire,
la modification par lot.
Chacun de ces modes offrent avantages et inconvénients qu'il faut avoir en tête pour utiliser Ishtar de manière optimale.
Import#
Mode opératoire#
Cela consiste en l'import de données dans Ishtar depuis un fichier « tableur » (format CSV).
Un « importeur » est utilisé afin d'extraire les données de ce fichier.
Cet « importeur » définit plusieurs choses, en particulier :
quel est le type de données à importer (des opérations, du mobilier, de la documentation, etc.) ;
un ordre de colonne précis ;
quelles sont les colonnes obligatoires ;
des formats de données attendus pour chaque colonne ;
une correspondance entre colonnes et champs de base de données (sachant que certains champs peuvent être constitués d'une concaténation de plusieurs colonnes) ;
des données par défaut ;
etc.
Une fois un fichier d'import rempli, depuis l'interface Ishtar, on procède à l'import effectif. Celui-ci se déroule en plusieurs phases :
création d'un import (où l'on spécifie le nom, le type d'importeur, le fichier à importer, etc.) ;
analyse du fichier à importer : Ishtar vérifie la cohérence de base du fichier et désigne d'éventuelles entrées à rapprocher ;
rapprochement entre des entrées du fichier du tableur et des listes de types fixes d'Ishtar : une table de correspondance est créée ;
import effectif des données.
Atouts#
Ce mode opératoire permet d'utiliser en amont des outils externes pour le raffinage des données (exemple : OpenRefine).
Les rapprochements permettent aussi une mise en correspondance facilitée des données.
La personne qui fournit les données n'a pas besoin de compte sur Ishtar : l'import peut être fait par un gestionnaire de données qui en amont fournit un exemple de fichier ou alors remodèle les données sources pour correspondre à l'importeur.
Dans le cadre d'intégration de données externes, le fichier d'import demeure afin de pouvoir ainsi remonter à la source des données et conserver l'historique.
Inconvénients#
Ce mode opératoire nécessite la création d'un importeur qui nécessite une forme d'expertise sur la base (connaître les champs obligatoires en création, générer correctement les identifiants depuis les colonnes, savoir faire correspondre les champs aux noms en base de données). Des importeurs sont disponibles de base dans Ishtar ;
L'importeur n'apporte pas de surcouche de contrôle, des données incohérentes dans le fichier source peuvent déclencher des erreurs en base de données et donner lieu à des messages d'erreur parfois assez peu explicites ;
Les données importées sont écrites dans la base de données directement, des données mal saisies dans le tableau importé ou un mauvais paramétrage d'importeur peuvent donner lieu à une destruction de données.
Cas d'utilisation#
C'est le mode opératoire à privilégier pour les sources de données externes à Ishtar que cela soit une reprise d'une base de données pré-existante ou une intégration de données d'autres intervenants.
En terme de mise à jour, ce mode opératoire peut être pertinent lors de la mise à jour de masse, notamment lorsque cette mise à jour est déléguée. En effet, avec un importeur ciblé sur les seules données à mettre à jour, ce mode peut être très efficace. Le contrôle du fichier avant import est aisé.
Ajout/modification par formulaire#
Mode opératoire#
L'ajout se fait via un enchaînement de formulaire web dans l'interface Ishtar. Ces formulaires sont découpés de manière thématique (exemple : formulaire « Conservation » de « Mobilier ») ou logique (le type d'opération est dans le premier formulaire Opération car il conditionne les formulaires suivants).
Chaque formulaire peut être personnalisé en ajoutant certains champs spécifiques (les champs personnalisés) ou en supprimant des champs de l'affichage. Ces personnalisations peuvent être faites pour tous ou simplement pour certains profils d'utilisateurs.
Atouts#
Notamment via les formulaires personnalisés, ce mode opératoire peut être un moyen efficace de saisie, en offrant des formulaires contextuels.
De base, ces formulaires présentent tous les champs disponibles, c'est la méthode la plus exhaustive.
Il existe différents facilitateurs de saisie, notamment :
auto-complétion de la saisie lorsque l'on chercher à lier à une commune ou à un autre élément principal d’Ishtar (opérations, sites archéologiques, unités d’enregistrement, mobilier, dépôts et contenants) ou dans les listes de vocabulaire contrôlé des champs avec typologie ;
filtres vers les éléments pertinents ; par exemple le champ Contenant parent d'un contenant ne liste que les contenants du lieu de conservation actuel ;
aide intelligente à la saisie ; par exemple création automatique d'une liste de parcelles depuis un champ texte simple de type "2013: XD:1 à 13,24,33 à 39, YD:24" ou bien conversion à la volée des dimensions (m vers km, g vers kg, m2 vers ha) pour vérifier sa saisie de dimensions importantes.
Inconvénients#
Cette saisie peut être longue et fastidieuse sur des gros volumes.
Cas d'utilisation#
Ce mode opératoire est particulièrement adapté à de la saisie/correction unitaire. Elle peut s'avérer pertinente pour une saisie terrain pour peu que l'on dispose de matériel adapté (tablette avec connexion Internet) et avec éventuellement des formulaires personnalisés afin de réduire la saisie aux seuls champs pertinents.
Modification par lot#
Mode opératoire#
Depuis les interfaces tableaux Ishtar, on fait une sélection multiple des lignes correspondant aux élément à modifier puis un clic sur le crayon vert permet d'accéder au formulaire de modification par lot.
Atouts#
Édition très rapide de champs sur plusieurs éléments.
Inconvénients#
La facilité et rapidité d'édition est propice aux erreurs si l'on n'est pas vigilant (un élément supplémentaire est vite sélectionné).
Le nombre de champs disponible est limité (il évolue régulièrement en fonction des demandes des utilisateurs mais cette liste n'est pas modifiable directement par les administrateurs fonctionnels, il faut faire appel aux développeurs).
Sur les champs multivalués (types de matériau par exemple), on ne peut actuellement qu'ajouter une nouvelle valeur, pas remplacer une valeur existante.
Cas d'utilisation#
Ce mode opératoire est particulièrement pertinent pour la correction en masse de données. Cela peut être aussi utile pour des travaux de pointage.
Notions avancées#
Données géographiques#
Les éléments principaux d’Ishtar (opérations, sites archéologiques, unités d’enregistrement, mobilier, dépôts et contenants) peuvent être localisés. Actuellement cette localisation est réalisée par le stockage de données géographiques (point ou polygone) parmi les champs de l'élément concerné. Dans une future version d'Ishtar, il est envisagé de créer des éléments distincts de type « Localisation » (qui correspondrait par exemple à un relevé topographique de terrain) auxquels les éléments principaux d'Ishtar pourraient être associés (de la même manière qu'un document est un élément distinct, auquel un ou des éléments parmi opération, site, UE, mobilier, dépôt et contenant peuvent être associés).
Un élément localisé dispose des champs suivants (entre parenthèses le nom du champ en base de données - à utiliser pour les configurations d'import) :
système de coordonnées géographiques utilisé (spatial_reference_system). Les systèmes de coordonnées standards sont présents par défaut dans Ishtar mais d'autres peuvent être ajoutés en administration.
coordonnées en x, y et z (x, y, z).
erreur estimée en x, y et z (estimated_error_x, estimated_error_y, estimated_error_z).
un champ point 2D (point_2d) et point 3D (point). Ce champ est déduit automatiquement des coordonnées (non visible en interface de saisie).
un champ polygone ou plus précisément un champ multi-polygone (multi_polygon) - par abus de langage polygone est repris dans la suite de la documentation. Pour l'instant ce champ n'est éditable qu'en import (mais visible sur les fiches) .
l'origine des coordonnées (point_source) et l'origine du polygone (multi_polygon_source). Trois origines sont possibles :
« précis » (valeur P pour precise). Les coordonnées ou le polygone ont été relevés précisément.
le polygone (valeur M pour multi-polygon). Ne concerne que le point : reprend le centroïde du polygone. Géré automatiquement par Ishtar quand le polygone a été défini précisément et qu'il n'y a pas de coordonnées précises associées.
la commune (valeur T pour town). Le point a été déduit du centroïde de la commune, le polygone reprend celui de la commune. Géré automatiquement par Ishtar quand aucune autre source n'est disponible.
la source des coordonnées (point_source_item), du polygone (multi_polygon_source_item). Quand l'élément n'a pas de coordonnées/de polygone associé, on essaye d'associer les coordonnées d'un élément parent, exemple : sans coordonnées précises, le mobilier a les coordonnées de son unité d'enregistrement qui elle-même hérite des coordonnées de l'opération ou du site archéologique associé si elle n'a pas de coordonnées propres. Cette mécanique est gérée automatiquement par Ishtar.
La gestion des données géographiques dans Ishtar est résumée par le graphe logique suivant pour les coordonnées :
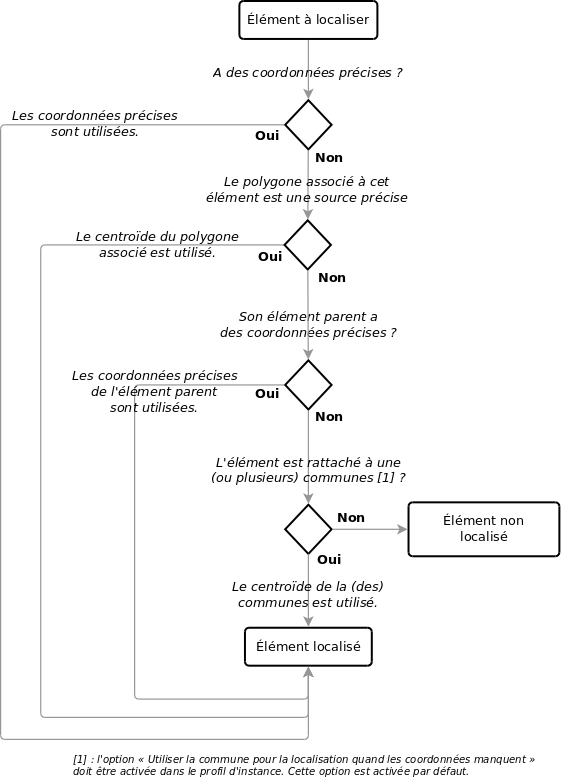
Gestion des coordonnées#
Pour les polygones, la gestion est assez similaire aux coordonnées mais sans la déduction possible depuis le polygone :
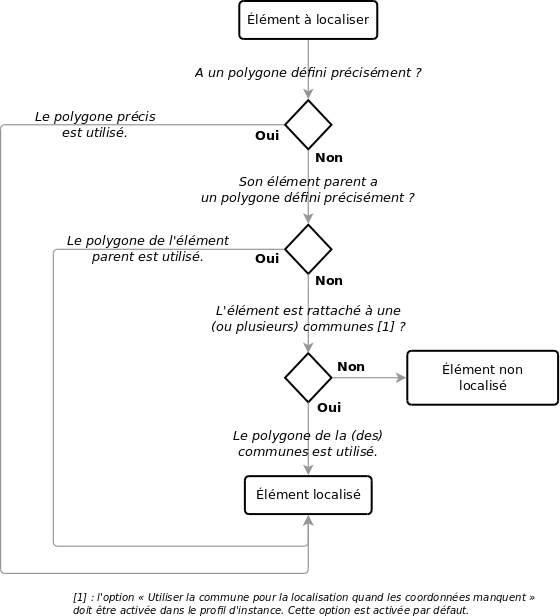
Gestion des polygones#
L'arbre de prise en compte des éléments parents pour les données géographiques est le suivant :
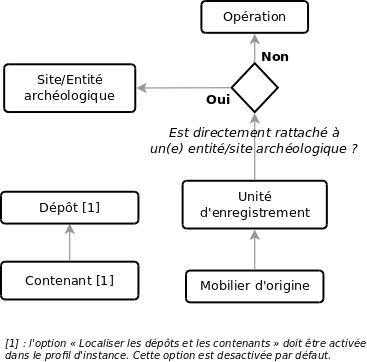
Note
Dans le profil d'instance, il est possible d'activer un degré d'imprécision. Cela permet de mettre un positionnement approximatif des éléments sur la fiche au cas où ces fiches seraient consultables par des tiers non dignes de confiance. Pour ce faire, les coordonnées sont tronquées (X nombres après la virgule) pour l'affichage (les données en base de données restent inchangées). La troncature est opérée sur les coordonnées en WGS 84 (latitude/longitude).